시각 인공지능은 생각보다 활용도가 넓다.
얼굴, 제스처, 차량 번호판, 객체탐지부터 이제는 생성 영역까지 확장되고 있다.
어차피 모든 것을 다 할 수는 없으니 기초 원리 + 데이터를 다루는 힘이 더 중요하다고 생각한다.
또한 실무는 점점 **RTUT(ready-to-use tool)**시대 즉 대규모 사전 학습 모델을 '잘 가져다 쓰고 튜닝하는 능력'이 중요해지고 있다.
즉 **기존 주요 모델(Backbone Network)를 잘 이해하고, 주어진 문제에 맞게 활용(hyperparameter 튜닝, 데이터 관리 등)**하는게 중요하지 않을까
개념잡기 - AI, 머신러닝, 딥러닝
기본적인 거지만 일단 학습하는 김에 다시 복습겸 정리를 해보자
인공지능(AI): 가장 넓은 개념으로 '기계가 사람처럼 생각하고, 학습하고, 판단하게 만드는 모든 기술'이다.
머신러닝(ML): 인공지능을 구현하는 **하나의 '방법'**이다. 기계에게 대량의 데이터를 주고, 그 데이터 속에서 스스로 규칙과 패턴을 **'학습'**하게 만드는 방식이다.
딥러닝(DL): 머신러닝 기법 중 하나로 인간의 뇌 신경망(뉴런) 구조를 모방한 '인공신경망' 기술을 사용한다.
이 신경망을 매우 깊게(Deep~) 쌓아서 복잡한 문제를 해결하는데 특화 되어 있다.
머신러닝은 어떻게 학습하는가
무엇으로 배우는가
지도 학습: 정답(Label)이 붙은 데이터로 학습한다. 정답과 해설이 있는 문제집으로 공부하는거다.
지도 학습은 크게 두 가지 문제를 해결하는 데 사용된다.
분류(Classification): 주어진 데이터가 어떤 카테고리에 속하는지 => 우리가 흔하게 본 개 vs 고양이 그거
회귀(Regression): 데이터의 패턴을 보고 특정 연속된 값을 예측하는 문제 => 로또 예측! 차트 예측! 어휴...
비지도 학습: 정답 없이 기계가 스스로 의미 있는 구조나 패턴 찾아내는 방식이다.
정답지가 없으니 데이터의 특성을 분석해 비슷한 것들끼리 **그룹을 만드는(군집화)**가 주된 목표다.
강화 학습: 에이전트라는 학습 주체가 특정 환경 안에서 행동하고 그 결과로 보상 또는 벌점을 받으면서 최적의 핼동 방식을 터득하는 학습법
Mission을 잘 완수했으니 「Reward」를 받아야겠지??
언제 어떻게 배우는가
배치 학습: 한번에 모든 데이터를 다 사용해서 모델을 훈련시킨 뒤, 현장에 배포하는 방식이다.
배포된 이후에는 더 이상 스스로 학습하지 않고 새로운 데이터가 생기거나 모델을 업데이트 하려면 전체 재학습이 필요하다.
온라인 학습: 새로운 데이터가 들어올 때마다 점진적으로 훈련하는 방식이다.
데이터를 하나씩 또는 작은 그룹 단위로 계속해서 학습한다.
어디선가 들어봤을 점진적 학습 (Incremental Learning) 개념이다.
시각 인공지능
대충 학습 방식 설명했으니 다시 시각 인공지능 범위로 돌아오자
**시각 인공지능(Visual AI)**은 기계에 인간과 같은 **'시각적 이해 능력'**을 부여하는 인공지능의 한 분야다.
본다! 로 끝나는게 아니고 이미지나 영상 속에 담긴 대상과 상황을 **인식(Recognize)**하고, 그 의미를 **해석(Interpret)**하며, 나아가 특정 **결정(Decision)**까지 내리게 하는 것을 목표로 한다.
인식 (Recognition): 고양이가 있네? => 객체 인식
해석 (Interpretation): 고양이가 웅크리고 있네? => 맥락을 이해
결정 (Decision): 쓰담쓰담쓰담 => 액션
과거 '시각 인공지능' 단어를 별로 못들어봤고, '객체 인식' 용어로 종종 들었던거 같은데, 인공지능이 스스로 '고양이'의 특징을 추출해내는 변화에서 용어도 바뀐게 아닐까?
컴퓨터 비전은 뭐임?
**컴퓨터 비전(Computer Vision)**이 더 넓은 학문적 분야다.
**시각 인공지능(Visual AI)**은 컴퓨터 비전이라는 '문제 영역'을 해결하기 위한 '최신 접근법'? 정도가 아닐까
인공지능 - 딥러닝 같은 관계려나
컴퓨터가 이미지를 '보는'방식
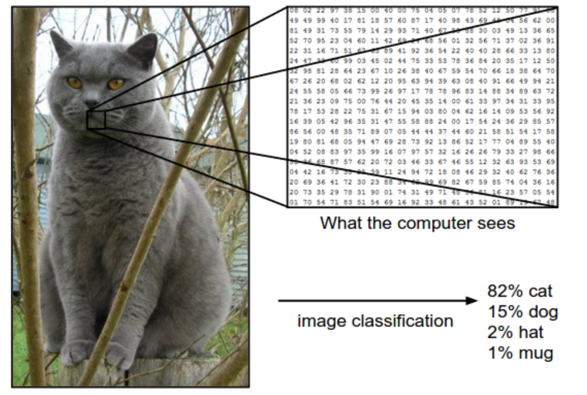
컴퓨터는 숫자로 이야기한다.
즉 이미지란 단지 정교하게 배열된 숫자의 집합이라는 것이다.
모든 것은 픽셀로부터
픽셀이 뭔지는 다들 알 테니 간단히 이야기하자면
픽셀 => 좌표(숫자 표현 가능) => 안에 있는건? 색상 코드(숫자 표현 가능)
즉 이미지를 컴퓨터가 다루기 위해 우리는 픽셀이라는 숫자 좌표 데이터와 컬러 라는 숫자 배열 데이터가 있다는 것이다.
'1920x1080' 해상도 = > 2,073,600개의 픽셀 데이터
(R, G, B) 컬러 => (0, 0, 0) ~ (255, 255, 255) 배열 데이터
컴퓨터를 위한 데이터 변환: 이미지를 텐서(Tensor)로
데이터만 있을 뿐이지 인공지능 모델이 이해할 수 있는건 아니다.
딥러닝 세계에서는 데이터 처리 표준 형식인 다차원 숫자 배열을 **텐서(Tensor)**라고 부른다.
이미지는 다음과 같이 텐서로 표현된다.
흑백 이미지 (Grayscale Image) 세로(Height)와 가로(Width)를 가진 2차원 텐서(행렬과 동일)로 표현된다.(밝기 값은 각 픽셀 위치마다 들어간다.)
- 형상(Shape):
(Height, Width)(예:(28, 28))
- 형상(Shape):
컬러 이미지 (Color Image) 세로(Height), 가로(Width)에 더해 색상 정보(Color Channels)라는 차원이 추가되어 3차원 텐서로 표현된다.
- 형상(Shape):
(Height, Width, Channels)(예:(256, 256, 3))
- 형상(Shape):
이미지 묶음 (Batch of Images) 딥러닝 모델은 보통 여러 장의 이미지를 한 번에 처리하여 학습 효율을 높힌다.
이렇게 여러 장의 이미지를 묶은 것을 **배치(Batch)**라고 하며, 이 경우 4차원 텐서가 사용된다.
- 형상(Shape):
(Batch_size, Height, Width, Channels)(예:(32, 256, 256, 3))
- 형상(Shape):
결론적으로, 시각 인공지능 모델에게 "고양이 사진을 입력한다"는 것은 사실 (배치 크기, 높이, 너비, 3) 형태를 가진 거대한 숫자의 집합, 즉 4D 텐서를 전달하는 것과 같다.
딥러닝의 데이터 처리 방식
갑자기 딥러닝을 다시 꺼내는 이유는 애가 데이터 처리하는 방식을 알아야하기 때문이다.
인공 신경망 기술을 쓰는데, 신경망 = 뉴런들이 깊게(Deep) 층을 이루어 서로 연결된 구조다.
잠깐 그 층에 대해서 알아보자
초기 층: 이미지의 가장 기본적인 요소인 선, 경계, 색상 변화 등을 감지
중간 층: 초기 층에서 감지한 선과 경계들을 조합해 눈,코,귀 같은 복잡한 형태 학습
마지막 층: 중간 층에서 학습한 형태롤 종합해 '고양이 얼굴'이나 '자동차 바퀴' 같은 구체적인 객체 인식
1층, 2층, 3층이 아니라 초기-중간-마지막이다.
즉 층이란게 필요한 만큼 Deep하게 구성되서 그 사이에서 서로 뉴런들이 연결되어 처리된다는 말이다.
딥러닝의 작동 원리
층 복잡한건 알았으니 데이터적인 측면을 보자
딥러닝의 학습 과정은 크게 '예측'과 '수정'의 두 단계로 나뉜다.
이 과정을 **순전파(Forward Propagation)**와 **역전파(Backpropagation)**라고 부른다.
순전파: 예측단계
이미지 데이터(텐서)가 신경망의 입력층으로 들어간다.
데이터는 마지막 층까지 통과하면서 처리되고 최종 예측값이 나온다.
오차 계산: 얼마나 틀렸는지 확인
모델이 내놓은 예측값과 실제 정답(레이블)을 비교해 얼마나 틀렸는지 계산한다.
이 오차의 크기를 손실(Loss) 또는 비용(Cost)라고 한다.
역전파: 수정, 학습 단계
계산된 오차를 바탕으로 이 오차에 각 뉴런이 얼마나 영향을 미쳤는지 역방향으로 추적해 계산한다.
그리고 각 뉴런의 연결 강도(가중치, Weight)를 오차를 줄이는 방향으로 아주 조금씩 수정한다.
위 과정을 오차가 만족스럽게 줄어들때까지 반복한다.
이미지 인식의 혁명 CNN(Convolutional Neural Network)
자 아까 설명한거
층 = Deep 하다.
뉴런 = 서로 지지리 복고 연결한다.
연산 = 앞으로 갔다가 뒤로 갔다가 반복한다.
그리고 중요한 데이터는?
256x256 크기의 컬러 이미지는 256 x 256 x 3 = 196,608 뉴런
데이터의 연산 속도는? 곱셉보다는 제곱에 가까울 것이다.
아무튼 느리다는 뜻이다.
어쨋든 성능에 문제가 있으니 방법을 고안해서 나온게 CNN이다.
지역적 정보 활용(Local Receptive Fields): 이미지 전체 대신 '필터'라는 작은 돋보기로 일부분만 보기
=> "이미지는 보통 주면 픽셀끼리 연관성이 높으니 다 볼 필요가 있을까?"
파라미터 공유(Parameter Sharing): 이미지의 왼쪽 위에서 '수직선'을 찾는 데 사용한 필터는 오른쪽 아래에서 '수직선'을 찾을 때도 동일하게 재사용 가능
=> "이 돋보기 가지고 싹다 돌려봐 수직선 바로 보임"
CNN 계층 구성
CNN은 주로 컨볼루션 계층과 풀링 계층을 반복적으로 쌓아 이미지 특징을 추출하고 마지막에 완전 연결 계층을 통해 최종 결정을 내린다.
Convolution Layer: 이미지의 특징을 추출하는 '필터'
**필터(Filter, 또는 커널)**를 사용하여 이미지의 특징을 뽑아낸다.
필터는 3x3, 5x5 크기의 작은 행렬로, 특정 패턴(수직선,수평선, 특정 색상 조합 등...)을 감지하는 역할을 한다.
일정 간격으로 나눠서 픽셀 값과 필터 값을 곱하고 모두 더해서 **특징 맵(Feature Map)**을 만든다.
Pooling Layer: 중요한 특징만 남기고 압축하는 '요약'
풀링 계층은 컨볼루션 계층을 통해 얻은 특징 맵의 크기를 줄여주는 역할을 한다.
데이터의 크기를 줄여 계산량을 감소시키고, 객체의 위치가 조금 변하더라도 동일한 특징으로 인식되도록 돕는다.
가장 널리 쓰이는 방식은 **최대 풀링(Max Pooling)**으로, 특징 맵을 일정 구역(예: 2x2)으로 나눈 뒤, 각 구역에서 가장 큰 값(가장 활성화된 특징)만 남기고 나머지는 버리는 방식이다.
Fully-Connected Layer: 종합된 특징으로 최종 판단을 내리는 '분류기'
여러 개의 컨볼루션과 풀링 계층을 거치고 나면, 작지만 핵심적인 특징 정보만을 담은 여러 개의 특징 맵으로 압축된다.(압축에 압축)
완전 연결 계층은 이 특징 맵들을 길게 일렬로 펼친 뒤(Flatten) 인공 신경망에 연결한다.
인공 신경망은 아예 쌩짜로 데이터 다 밀어 넣는 대신 추출된 모든 고차원 특징들('수염', '둥근 눈' 같은거)가지고 최종적인 분류(Classification) 결과를 출력한다.
쓰다보니 시간이 모잘라 2편에서 계속...